Cómo se rompen y se reparan los sistemas reales.
Publicaciones organizadas por dominio técnico. Cada tarjeta abre el artículo completo. Material en colaboración con Cardano Castellano, Techne Secure y notas propias de investigación.

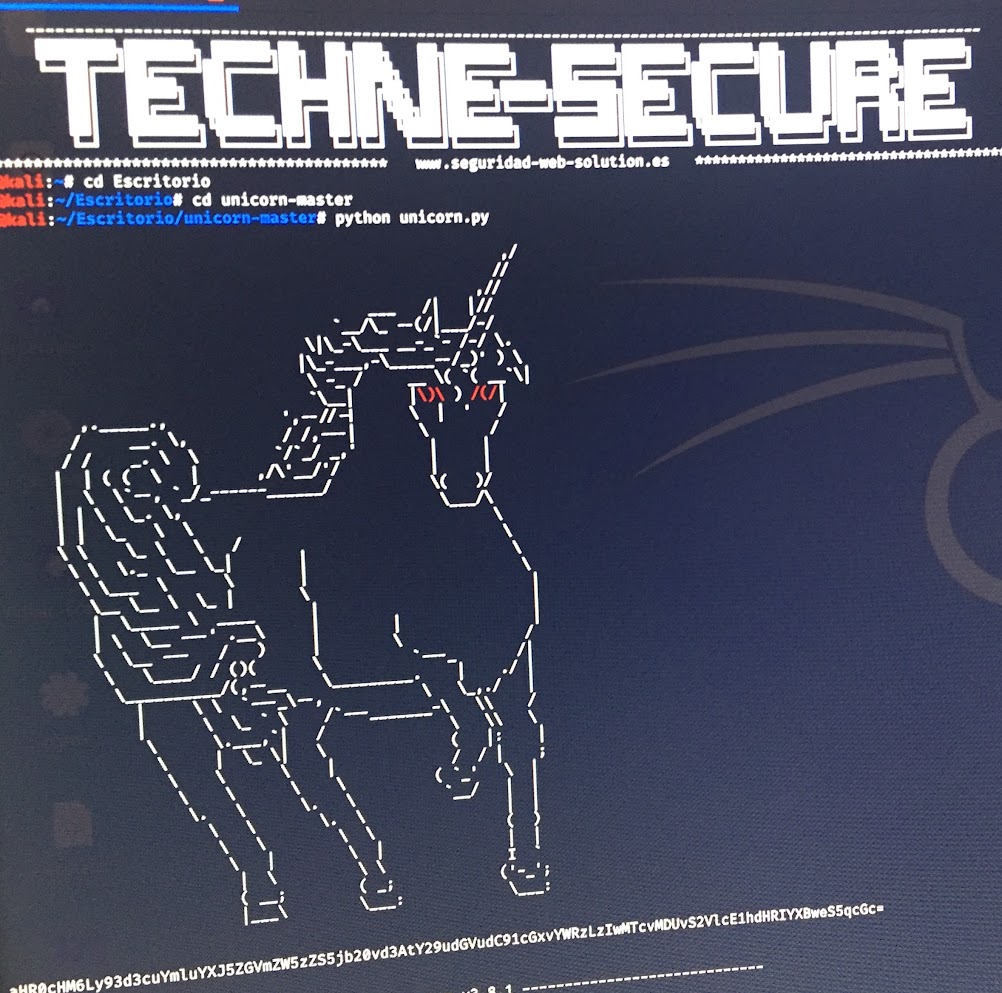
Análisis de vectores de entrada y seguridad de nodos
Sesión metodológica sobre perímetros de red expuestos en validadores y pautas de mitigación ante amenazas de denegación de servicio a nivel de protocolo.

Respuesta a incidentes en remoto durante 2020: lo que cambió y lo que no
Lecciones aprendidas gestionando incidentes de seguridad con equipos 100% distribuidos: cadena de custodia digital, comunicación segura fuera de banda y reconstrucción de timeline.

El coste de la prisa: por qué la auditoría de seguridad es el cimiento de la resiliencia arquitectónica
Las 13 capas de la superficie de ataque empresarial, el caso Silent Breach y por qué la velocidad de despliegue sin auditoría es negligencia técnica, no agilidad.

Hardening empresarial de Kubernetes y AWS en producción
Configuraciones esenciales para aislar pods, mitigar escaladas de privilegios en Service Accounts y auditoría automatizada de políticas IAM restrictivas.

Zero Trust en una organización multi-cloud: más allá del marketing
Implementación práctica de los principios Zero Trust en una arquitectura con cargas en AWS, GCP y on-premise: identidad como perímetro, dispositivos verificados y políticas continuas.
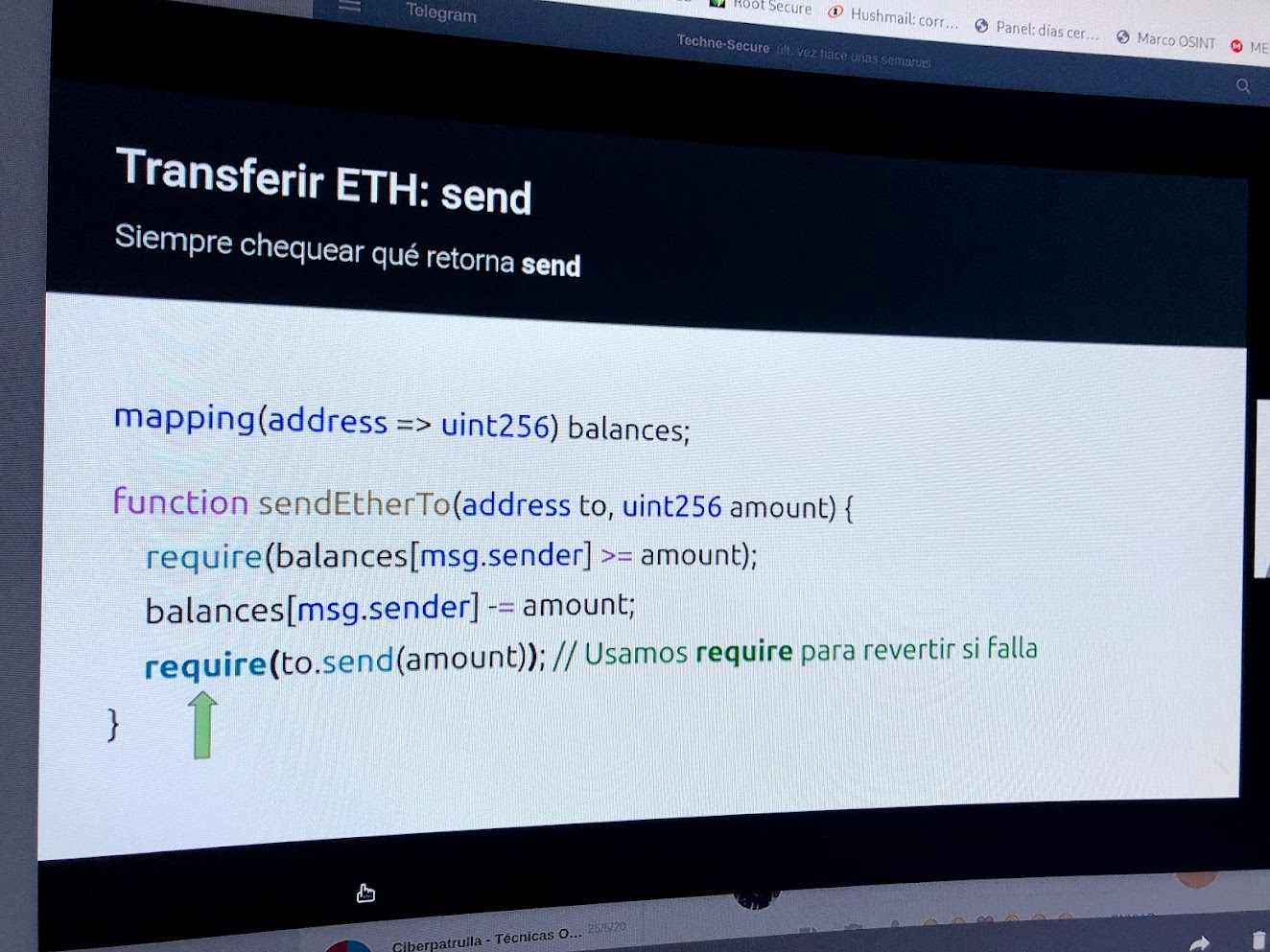


Bastionado de servidores Linux en producción: del default a CIS
Guía operativa para endurecer un servidor Debian/CentOS recién provisionado siguiendo controles del CIS Benchmark, con énfasis en SSH, auditd y módulos del kernel.

Diseño de una infraestructura LAMP de alta disponibilidad
Arquitectura de referencia para servir aplicaciones PHP críticas: Apache/Nginx detrás de HAProxy, replicación MySQL maestro-réplica, GlusterFS para archivos compartidos y monitorización con Nagios.



// contact
¿Evaluando la seguridad de tu infraestructura?
Auditorías de arquitectura cloud, análisis forense, simulaciones Red Team o proyectos de automatización segura.
jgomezsecure@protonmail.com →